4.8. Real Numbers in Binary
While this chapter mainly focuses on binary integer representations, programmers often need to store real numbers, too. Storing real numbers is inherently difficult, and no binary encoding represents real values with perfect precision. That is, for any binary encoding of real numbers, there exist values that cannot be represented exactly. Irrational values like pi clearly can’t be represented precisely, since their representation never terminates. Given a fixed number of bits, binary encodings still can’t represent some rational values within their range.
Unlike integers, which are countably infinite, the set of real numbers is uncountable. In other words, even for a narrow range of real values (e.g., between zero and one), the set of values within that range is so large that we can’t even begin to enumerate them. Thus, real number encodings typically store only approximations of values that have been truncated to a predetermined number of bits. Given enough bits, the approximations are typically precise enough for most purposes, but be careful when writing applications that cannot tolerate rounding.
The remainder of this section briefly describes two methods for representing real numbers in binary: fixed-point, which extends the binary integer format, and floating-point, which represents a large range of values at the cost of some extra complexity.
4.8.1. Fixed-Point Representation
In a fixed-point representation, the position of a value’s binary point remains fixed and cannot be changed. Like a decimal point in a decimal number, the binary point indicates where the fractional portion of the number begins. The fixed-point encoding rules resemble the unsigned integer representation, with one major exception: the digits after the binary point represent powers of two raised to a negative value. For example, consider the eight-bit sequence 0b000101.10 in which the first six bits represent whole numbers, and the remaining two bits represent the fractional part. Figure 1 labels the digit positions and their individual interpretations.

Applying the formula for converting 0b000101.10 to decimal shows:
More generally, with two bits after the binary point, the fractional portion of a number holds one of four sequences: 00 (.00), 01 (.25), 10 (.50), or 11 (.75). Thus, two fractional bits allow a fixed-point number to represent fractional values that are precise to 0.25 (2-2). Adding a third bit increases the precision to 0.125 (2-3), and the pattern continues similarly, with N bits after the binary point enabling 2-N precision.
Because the number of bits after the binary point remains fixed, some computations with fully precise operands may produce a result that requires truncation (rounding). Consider the same eight-bit fixed-point encoding from the previous example. It precisely represents both 0.75 (0b000000.11) and 2 (0b000010.00). However, it cannot precisely represent the result of dividing 0.75 by 2: the computation should produce 0.375, but storing it would require a third bit after the binary point (0b000000.011). Truncating the rightmost 1 enables the result to fit within the specified format, but it yields a rounded result of 0.75 / 2 = 0.25. In this example, the rounding is egregious due to the small number of bits involved, but even longer bit sequences will require truncation at some point.
Even worse, rounding errors compound over the course of intermediate calculations, and in some cases the result of a sequence of computations might vary according to the order in which they’re performed. For example, consider two arithmetic sequences under the same eight-bit fixed-point encoding described earlier:
-
(0.75 / 2) * 3 = 0.75 -
(0.75 * 3) / 2 = 1.00
Note that the only difference between the two is the order of the multiplication and division operations. If no rounding were necessary, both computations should produce the same result (1.125). However, due to truncation occurring at different locations in the arithmetic, they produce different results:
-
Proceeding from left to right, the intermediate result (
0.75 / 2) gets rounded to 0.25 and ultimately produces 0.75 when multiplied by 3. -
Proceeding from left to right, the intermediate computation (
0.75 * 3) precisely yields 2.25 without any rounding. Dividing 2.25 by 2 rounds to a final result of 1.
In this example, just one additional bit for the 2-3 place allows the example to succeed with full precision, but the fixed-point position we chose only allowed for two bits after the binary point. All the while, the high-order bits of the operands went entirely unused (digits d2 through d5 were never set to 1). At the cost of extra complexity, an alternative representation (floating-point) allows the full range of bits to contribute to a value regardless of the split between whole and fractional parts.
4.8.2. Floating-Point Representation
In a floating-point representation, a value’s binary point is not fixed into a predefined position. That is, the interpretation of a binary sequence must encode how it’s representing the split between the whole and fractional parts of a value. While the position of the binary point could be encoded in many possible ways, this section focuses on just one, the Institute of Electrical and Electronics Engineers (IEEE) standard 754. Almost all modern hardware follows the IEEE 754 standard to represent floating-point values.
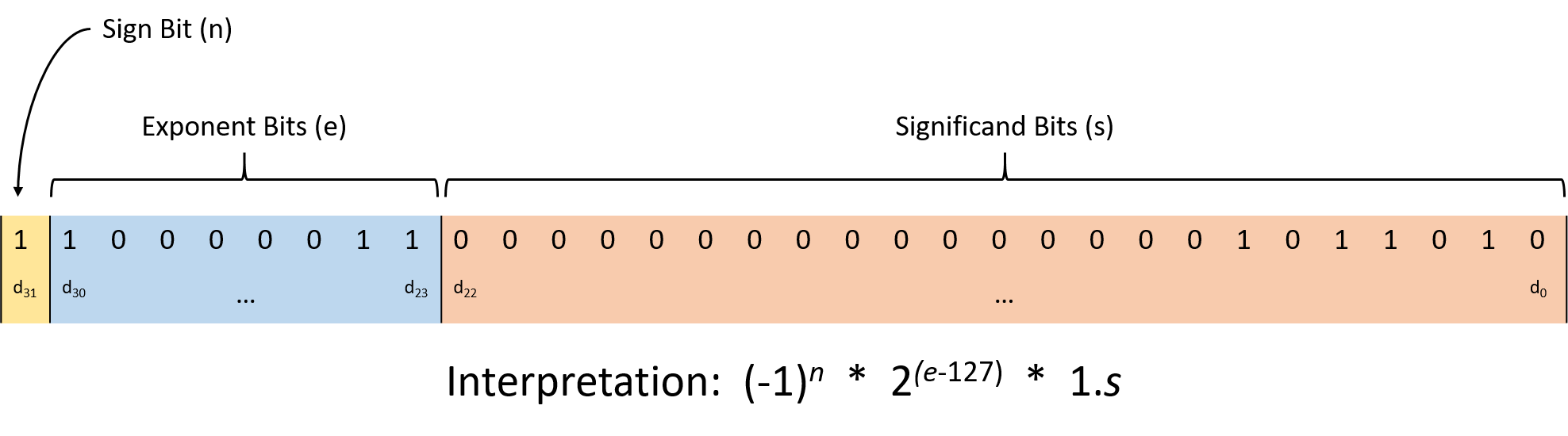
Figure 2 illustrates the IEEE 754 interpretation of a 32-bit
floating-point number (C’s float type). The standard partitions the bits
into three regions:
-
The low-order 23 bits (digits d22 through d0) represent the significand (sometimes called the mantissa). As the largest region of bits, the significand serves as the foundation for the value, which ultimately gets altered by multiplying it according to the other bit regions. When interpreting the significand, its value implicitly follows a 1 and binary point. The fractional portion behaves like the fixed-point representation described in the previous section.
For example, if the bits of the significand contain 0b110000…0000, the first bit represents 0.5 (1 × 2-1), the second bit represents 0.25 (1 × 2-2), and all the remaining bits are zeros, so they don’t affect the value. Thus, the significand contributes 1.(0.5 + 0.25), or 1.75.
-
The next eight bits (digits d30 through d23) represent the exponent, which scales the significand’s value to provide a wide representable range. The significand gets multiplied by 2exponent - 127, where the 127 is a bias that enables the float to represent both very large and very small values.
-
The final high-order bit (digit d31) represents the sign bit, which encodes whether the value is positive (0) or negative (1).
As an example, consider decoding the bit sequence 0b11000001101101000000000000000000. The significand portion is 01101000000000000000000, which represents 2-2 + 2-3 + 2-5 = 0.40625, so the signifcand region contributes 1.40625. The exponent is 10000011, which represents the decimal value 131, so the exponent contributes a factor of 2(131-127) (16). Finally, the sign bit is 1, so the sequence represents a negative value. Putting it all together, the bit sequence represents:
1.40625 × 16 × -1 = -22.5
While clearly more complex than the fixed-point scheme described earlier, the IEEE floating-point standard provides additional flexibility for representing a wide range of values. Despite the flexibility, a floating-point format with a constant number of bits still can’t precisely represent every possible value. That is, like fixed-point, rounding problems similarly affect floating-point encodings.
4.8.3. Rounding Consequences
While rounding isn’t likely to ruin most of the programs you write, real number rounding errors have occasionally caused some high-profile system failures. During the Gulf War in 1991, a rounding error caused an American Patriot missile battery to fail to intercept an Iraqi missile. The missile killed 28 soldiers and left many others wounded. In 1996, the European Space Agency’s first launch of the Ariane 5 rocket exploded 39 seconds after taking off. The rocket, which borrowed much of its code from the Ariane 4, triggered an overflow when attempting to convert a floating-point value into an integer value.