14.3.1. Mutual Exclusion
What is the mutex? The answer is out there, and it’s looking for you, and it will find you if you want it to.
~Trinity, explaining mutexes to Neo (Apologies to The Matrix)
To fix the data race, let’s use a synchronization construct known as a mutual exclusion lock, or mutex. Mutual exclusion locks are a type of synchronization primitive that ensures that only one thread enters and executes the code inside the critical section at any given time.
Before using a mutex, a program must first:
-
Declare the mutex in memory that’s shared by threads (often as a global variable).
-
Initialize the mutex before the threads need to use it (typically in the
mainfunction).
The Pthreads library defines a pthread_mutex_t type for mutexes. To declare
a mutex variable, add this line:
pthread_mutex_t mutex;To initialize the mutex use the pthread_mutex_init function, which takes
the address of a mutex and an attribute structure, typically set to NULL:
pthread_mutex_init(&mutex, NULL);When the mutex is no longer needed (typically at the end of the main function,
after pthread_join), a program should release the mutex structure by invoking
the pthread_mutex_destroy function:
pthread_mutex_destroy(&mutex);The Mutex: Locked and Loaded
The initial state of a mutex is unlocked, meaning it’s immediately usable by any
thread. To enter a critical section, a thread must first acquire a lock. This is
accomplished with a call to the pthread_mutex_lock function. After a
thread has the lock, no other thread can enter the critical section until the
thread with the lock releases it. If another thread calls pthread_mutex_lock
and the mutex is already locked, the thread will block (or wait) until the
mutex becomes available. Recall that blocking
implies that the thread will not be scheduled to use the CPU until the
condition it’s waiting for (the mutex being available) becomes true.
When a thread exits the critical section it must call the
pthread_mutex_unlock function to release the mutex, making it available for
another thread. Thus, at most one thread may acquire the lock and enter the
critical section at a time, which prevents multiple threads from racing to
read and update shared variables.
Having declared and initialized a mutex, the next question is where the lock
and unlock functions should be placed to best enforce the critical section.
Here is an initial attempt at augmenting the countElems function with a mutex
(The full source can be downloaded from
countElems_p_v2.c):
pthread_mutex_t mutex; //global declaration of mutex, initialized in main()
/*parallel version of step 1 of CountSort algorithm (attempt 1 with mutexes):
* extracts arguments from args value
* calculates component of the array that thread is responsible for counting
* computes the frequency of all the elements in assigned component and stores
* the associated counts of each element in counts array
*/
void *countElems( void *args ) {
//extract arguments
//ommitted for brevity
int *array = myargs->ap;
long *counts = myargs->countp;
//assign work to the thread
long chunk = length / nthreads; //nominal chunk size
long start = myid * chunk;
long end = (myid + 1) * chunk;
long val;
if (myid == nthreads - 1) {
end = length;
}
long i;
//heart of the program
pthread_mutex_lock(&mutex); //acquire the mutex lock
for (i = start; i < end; i++) {
val = array[i];
counts[val] = counts[val] + 1;
}
pthread_mutex_unlock(&mutex); //release the mutex lock
return NULL;
}The mutex initialize and destroy functions are placed in main around the
thread creation and join functions:
//code snippet from main():
pthread_mutex_init(&mutex, NULL); //initialize the mutex
for (t = 0; t < nthreads; t++) {
pthread_create( &thread_array[t], NULL, countElems, &thread_args[t] );
}
for (t = 0; t < nthreads; t++) {
pthread_join(thread_array[t], NULL);
}
pthread_mutex_destroy(&mutex); //destroy (free) the mutexLet’s recompile and run this new program while varying the number of threads:
$ ./countElems_p_v2 10000000 1 1 Counts array: 999170 1001044 999908 1000431 999998 1001479 999709 997250 1000804 1000207 $ ./countElems_p_v2 10000000 1 2 Counts array: 999170 1001044 999908 1000431 999998 1001479 999709 997250 1000804 1000207 $ ./countElems_p_v2 10000000 1 4 Counts array: 999170 1001044 999908 1000431 999998 1001479 999709 997250 1000804 1000207
Excellent, the output is finally consistent regardless of the number of threads used!
Recall that another primary goal of threading is to reduce the runtime of a
program as the number of threads increases (in other words, to speed up program execution).
Let’s benchmark the performance of the countElems function. Although it may
be tempting to use a command line utility like time -p, recall that
invoking time -p measures the wall-clock time of the entire program (including the generation of random
elements) and not just the running of the countElems function. In this
case, it is better to use a system call like gettimeofday, which allows
a user to accurately measure the wall-clock time of a particular section of code.
Benchmarking countElems on 100 million elements yields the following run
times:
$ ./countElems_p_v2 100000000 0 1 Time for Step 1 is 0.368126 s $ ./countElems_p_v2 100000000 0 2 Time for Step 1 is 0.438357 s $ ./countElems_p_v2 100000000 0 4 Time for Step 1 is 0.519913 s
Adding more threads causes the program to get slower! This goes against the goal of making programs faster with threads.
To understand what is going on, consider where the locks are placed in the
countsElems function:
//code snippet from the countElems function from earlier
//the heart of the program
pthread_mutex_lock(&mutex); //acquire the mutex lock
for (i = start; i < end; i++){
val = array[i];
counts[val] = counts[val] + 1;
}
pthread_mutex_unlock(&mutex); //release the mutex lockIn this example, we placed the lock around the entirety of the for loop.
Even though this placement solves the correctness problems, it’s an extremely poor
decision from a performance perspective — the critical section now encompasses
the entire loop body. Placing locks in this manner guarantees that only one
thread can execute the loop at a time, effectively serializing the program!
The Mutex: Reloaded
Let’s try another approach and place the mutex locking and unlocking functions within every iteration of the loop:
/*modified code snippet of countElems function:
*locks are now placed INSIDE the for loop!
*/
//the heart of the program
for (i = start; i < end; i++) {
val = array[i];
pthread_mutex_lock(&m); //acquire the mutex lock
counts[val] = counts[val] + 1;
pthread_mutex_unlock(&m); //release the mutex lock
}This may initially look like a better solution because each thread can enter
the loop in parallel, serializing only when reaching the lock. The critical
section is very small, encompassing only the line counts[val] = counts[val] + 1.
Let’s first perform a correctness check on this version of the program:
$ ./countElems_p_v3 10000000 1 1 Counts array: 999170 1001044 999908 1000431 999998 1001479 999709 997250 1000804 1000207 $ ./countElems_p_v3 10000000 1 2 Counts array: 999170 1001044 999908 1000431 999998 1001479 999709 997250 1000804 1000207 $ ./countElems_p_v3 10000000 1 4 Counts array: 999170 1001044 999908 1000431 999998 1001479 999709 997250 1000804 1000207
So far so good. This version of the program also produces consistent output regardless of the number of threads employed.
Now, let’s look at performance:
$ ./countElems_p_v3 100000000 0 1 Time for Step 1 is 1.92225 s $ ./countElems_p_v3 100000000 0 2 Time for Step 1 is 10.9704 s $ ./countElems_p_v3 100000000 0 4 Time for Step 1 is 9.13662 s
Running this version of the code yields (amazingly enough) a significantly slower runtime!
As it turns out, locking and unlocking a mutex are expensive operations. Recall what was covered in the discussion on function call optimizations: calling a function repeatedly (and needlessly) in a loop can be a major cause of slowdown in a program. In our prior use of mutexes, each thread locks and unlocks the mutex exactly once. In the current solution, each thread locks and unlocks the mutex n/t times, where n is the size of the array, t is the number of threads, and n/t is the size of the array component assigned to each particular thread. As a result, the cost of the additional mutex operations slows down the loop’s execution considerably.
The Mutex: Revisited
In addition to protecting the critical section to achieve correct behavior, an ideal solution would use the lock and unlock functions as little as possible, and reduce the critical section to the smallest possible size.
The original implementation satisfies the first requirement, whereas the second implementation tries to accomplish the second. At first glance, it appears that the two requirements are incompatible with each other. Is there a way to actually accomplish both (and while we are at it, speed up the execution of our program)?
For the next attempt, each thread maintains a private, local array of counts on its stack. Because the array is local to each thread, a thread can access it without locking — there’s no risk of a race condition on data that isn’t shared between threads. Each thread processes its assigned subset of the shared array and populates its local counts array. After counting up all the values within its subset, each thread:
-
Locks the shared mutex (entering a critical section).
-
Adds the values from its local counts array to the shared counts array.
-
Unlocks the shared mutex (exiting the critical section).
Restricting each thread to update the shared counts array only once significantly reduces the contention for shared variables and minimizes expensive mutex operations.
The following is our revised countElems function. The full source code for this final
program can be accessed at (countElems_p_v3.c):
/*parallel version of step 1 of CountSort algorithm (final attempt w/mutexes):
* extracts arguments from args value
* calculates component of the array that thread is responsible for counting
* computes the frequency of all the elements in assigned component and stores
* the associated counts of each element in counts array
*/
void *countElems( void *args ) {
//extract arguments
//ommitted for brevity
int *array = myargs->ap;
long *counts = myargs->countp;
//local declaration of counts array, initializes every element to zero.
long local_counts[MAX] = {0};
//assign work to the thread
long chunk = length / nthreads; //nominal chunk size
long start = myid * chunk;
long end = (myid + 1) * chunk;
long val;
if (myid == nthreads-1)
end = length;
long i;
//heart of the program
for (i = start; i < end; i++) {
val = array[i];
//updates local counts array
local_counts[val] = local_counts[val] + 1;
}
//update to global counts array
pthread_mutex_lock(&mutex); //acquire the mutex lock
for (i = 0; i < MAX; i++) {
counts[i] += local_counts[i];
}
pthread_mutex_unlock(&mutex); //release the mutex lock
return NULL;
}This version has a few additional features:
-
The presence of
local_counts, an array that is private to the scope of each thread (i.e., allocated in the thread’s stack). Likecounts,local_countscontainsMAXelements, given thatMAXis the maximum value any element can hold in our input array. -
Each thread makes updates to
local_countsat its own pace, without any contention for shared variables. -
A single call to
pthread_mutex_lockprotects each thread’s update to the globalcountsarray, which happens only once at the end of each thread’s execution.
In this manner, we reduce the time each thread spends in a critical section to
just updating the shared counts array. Even though only one thread can enter
the critical section at a time, the time each thread spends there is
proportional to MAX, not n, the length of the global array. Since MAX
is much less than n, we should see an improvement in performance.
Let’s now benchmark this version of our code:
$ ./countElems_p_v3 100000000 0 1 Time for Step 1 is 0.334574 s $ ./countElems_p_v3 100000000 0 2 Time for Step 1 is 0.209347 s $ ./countElems_p_v3 100000000 0 4 Time for Step 1 is 0.130745 s
Wow, what a difference! Our program not only computes the correct answers, but also executes faster as we increase the number of threads.
The lesson to take away here is this: to efficiently minimize a critical section, use local variables to collect intermediate values. After the hard work requiring parallelization is over, use a mutex to safely update any shared variable(s).
Deadlock
In some programs, waiting threads have dependencies on one another. A situation called deadlock can arise when multiple synchronization constructs like mutexes are incorrectly applied. A deadlocked thread is blocked from execution by another thread, which itself is blocked on a blocked thread. Gridlock (in which cars in all directions cannot move forward due to being blocked by other cars) is a common real-world example of deadlock that occurs at busy city intersections.
To illustrate a deadlock scenario in code, let’s consider an example where multithreading is used to implement a banking application. Each user’s account is defined by a balance and its own mutex (ensuring that no race conditions can occur when updating the balance):
struct account {
pthread_mutex_t lock;
int balance;
};Consider the following naive implementation of a Transfer function that moves money
from one bank account to another:
void *Transfer(void *args){
//argument passing removed to increase readability
//...
pthread_mutex_lock(&fromAcct->lock);
pthread_mutex_lock(&toAcct->lock);
fromAcct->balance -= amt;
toAcct->balance += amt;
pthread_mutex_unlock(&fromAcct->lock);
pthread_mutex_unlock(&toAcct->lock);
return NULL;
}Suppose that Threads 0 and 1 are executing concurrently and represent users A and B, respectively. Now consider the situation in which A and B want to transfer money to each other: A wants to transfer 20 dollars to B, while B wants to transfer 40 to A.
In the path of execution highlighted by Figure 1, both threads concurrently execute the Transfer
function. Thread 0 acquires the lock of acctA while Thread 1 acquires the lock of acctB. Now consider
what happens. To continue executing, Thread 0 needs to acquire the lock on acctB, which Thread 1 holds.
Likewise, Thread 1 needs to acquire the lock on acctA to continue executing, which Thread 0 holds. Since
both threads are blocked on each other, they are in deadlock.
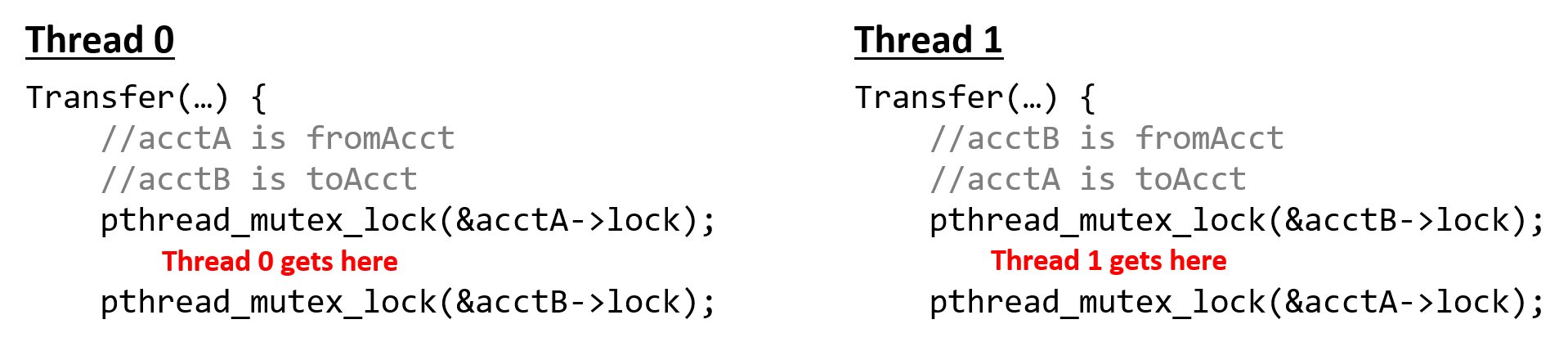
Although the OS provides some protection against deadlock, programmers should be mindful about writing code that increases the likelihood of deadlock. For example, the preceding scenario could have been avoided by rearranging the locks so that each lock/unlock pair surrounds only the balance update statement associated with it:
void *Transfer(void *args){
//argument passing removed to increase readability
//...
pthread_mutex_lock(&fromAcct->lock);
fromAcct->balance -= amt;
pthread_mutex_unlock(&fromAcct->lock);
pthread_mutex_lock(&toAcct->lock);
toAcct->balance += amt;
pthread_mutex_unlock(&toAcct->lock);
return NULL;
}Deadlock is not a situation that is unique to threads. Processes (especially those that are communicating with one another) can deadlock with one another. Programmers should be mindful of the synchronization primitives they use and the consequences of using them incorrectly.