14.5. Cache Coherence and False Sharing
Multicore caches can have profound implications on a multithreaded program’s performance. First, however, let’s quickly review some of the basic concepts related to cache design:
-
Data/instructions are not transported individually to the cache. Instead, data is transferred in blocks, and block sizes tend to get larger at lower levels of the memory hierarchy.
-
Each cache is organized into a series of sets, with each set having a number of lines. Each line holds a single block of data.
-
The individual bits of a memory address are used to determine which set, tag, and block offset of the cache to which to write a block of data.
-
A cache hit occurs when the desired data block exists in the cache. Otherwise, a cache miss occurs, and a lookup is performed on the next lower level of the memory hierarchy (which can be cache or main memory).
-
The valid bit indicates if a block at a particular line in the cache is safe to use. If the valid bit is set to 0, the data block at that line cannot be used (e.g., the block could contain data from an exited process).
-
Information is written to cache/memory based on two main strategies. In the write-through strategy, the data is written to cache and main memory simultaneously. In the write-back strategy, data is written only to cache and gets written to lower levels in the hierarchy after the block is evicted from the cache.
14.5.1. Caches on Multicore Systems
Recall that, in shared memory architectures, each core can have its own cache and that multiple cores can share a common cache. Figure 1 depicts an example dual-core CPU. Even though each core has its own local L1 cache, the cores share a common L2 cache.
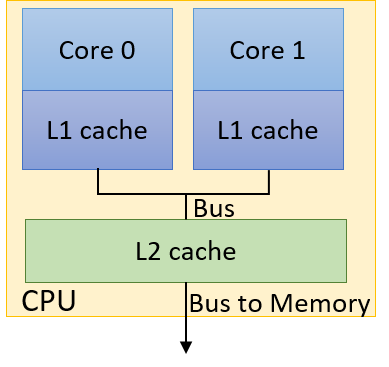
Multiple threads in a single executable may execute separate functions. Without a
cache coherence strategy
to ensure that each cache maintains a consistent view of shared memory, it is possible for shared variables
to be updated inconsistently. As an example, consider the dual-core processor in
Figure 1, where each core is busy executing separate threads
concurrently. The thread assigned to Core 0 has a local variable x, whereas the
thread executing on Core 1 has a local variable y, and both threads have
shared access to a global variable g. Table 1 shows one possible path
of execution.
| Time | Core 0 | Core 1 |
|---|---|---|
0 |
g = 5 |
(other work) |
1 |
(other work) |
y = g*4 |
2 |
x += g |
y += g*2 |
Suppose that the initial value of g is 10, and the initial values of x and y
are both 0. What is the final value of y at the end of this sequence
of operations? Without cache coherence, this is a very difficult question to answer, given
that there are at
least three stored values of g: one in Core 0’s L1 cache, one in Core 1’s L1
cache, and a separate copy of g stored in the shared L2 cache.
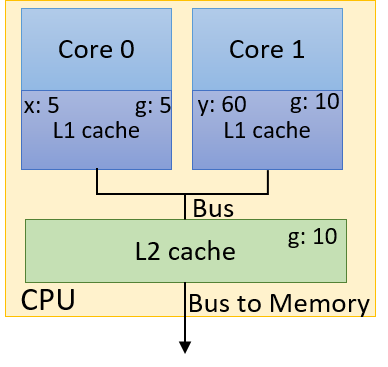
Figure 2 shows one possible erroneous result after the sequence of operations
in Table 1 completes. Suppose that the L1 caches implement a write-back
policy. When the thread executing on Core 0 writes the value 5 to g, it
updates only the value of g in Core 0’s L1 cache. The value of g in Core 1’s L1
cache still remains 10, as does the copy in the shared L2 cache. Even if a
write-through policy is implemented, there is no guarantee that the copy of
g stored in Core 1’s L1 cache gets updated! In this case, y will have
the final value of 60.
A cache coherence strategy invalidates or updates cached copies of shared values in other caches when a write to the shared data value is made in one cache. The Modified Shared Invalid (MSI) protocol (discussed in detail in Chapter 11.6) is one example of an invalidating cache coherency protocol.
A common technnique for implementing MSI is snooping. Such a snoopy cache "snoops" on the memory bus for possible write signals. If the snoopy cache detects a write to a shared cache block, it invalidates its line containing that cache block. The end result is that the only valid version of the block is in the cache that is written to, whereas all other copies of the block in other caches are marked as invalid.
Employing the MSI protocol with snoooping would yield
the correct final assignment of 30 to variable y in the previous example.
14.5.2. False Sharing
Cache coherence guarantees correctness, but it can potentially harm
performance. Recall that when the thread updates g on Core 0, the snoopy
cache invalidates not only g, but the entire cache line that g is a
part of.
Consider our initial attempt at
parallelizing the countElems function of the CountSort algorithm. For
convenience, the function is reproduced here:
/*parallel version of step 1 (first cut) of CountSort algorithm:
* extracts arguments from args value
* calculates portion of the array this thread is responsible for counting
* computes the frequency of all the elements in assigned component and stores
* the associated counts of each element in counts array
*/
void *countElems(void *args){
//extract arguments
//ommitted for brevity
int *array = myargs->ap;
long *counts = myargs->countp;
//assign work to the thread
//compute chunk, start, and end
//ommited for brevity
long i;
//heart of the program
for (i = start; i < end; i++){
val = array[i];
counts[val] = counts[val] + 1;
}
return NULL;
}In our previous discussion of
this function, we pointed out how data races can cause the counts array to
not populate with the correct set of counts. Let’s see what happens if we
attempt to time this function. We add timing code to main using
getimeofday in the exact manner as shown in
countElems_p_v3.c. Benchmarking the
initial version of countElems as just shown on 100 million elements yields
the following times:
$ ./countElems_p 100000000 0 1 Time for Step 1 is 0.336239 s $ ./countElems_p 100000000 0 2 Time for Step 1 is 0.799464 s $ ./countElems_p 100000000 0 4 Time for Step 1 is 0.767003 s
Even without any synchronization constructs, this version of the program still gets slower as the number of threads increases!
To understand what is going on, let’s revisit the counts array. The counts
array holds the frequency of occurrence of each number in our input array.
The maximum value is determined by the variable MAX. In our example program,
MAX is set to 10. In other words, the counts array takes up 40 bytes of
space.
Recall that the
cache details
on a Linux system are located in the
/sys/devices/system/cpu/ directory. Each logical core has its own cpu subdirectory
called cpuk where k indicates the kth logical core. Each cpu subdirectory in turn
has separate index directories that indicate the caches available to that core.
The index directories contain files with numerous details about each logical core’s caches. The contents of a sample index0 directory are shown here
(index0 typically corresponds to a Linux system’s L1 cache):
$ ls /sys/devices/system/cpu/cpu0/cache/index0 coherency_line_size power type level shared_cpu_list uevent number_of_sets shared_cpu_map ways_of_associativity physical_line_partition size
To discover the cache line size of the L1 cache, use this command:
$ cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size 64
The output reveals that L1 cache line size for the
machine is 64 bytes. In other words, the 40-byte counts array fits within
one cache line.
Recall that with invalidating cache coherence protocols like MSI, every time a program updates a shared
variable, the entire cache line in other caches storing the variable is
invalidated. Let’s consider what happens when two threads execute the preceding
function. One possible path of execution is shown in Table 2
(assuming that each thread is
assigned to a separate core, and the variable x is local to each thread).
| Time | Thread 0 | Thread 1 |
|---|---|---|
i |
Reads array[x] (1) |
… |
i+1 |
Increments counts[1] (invalidates cache line) |
Reads array[x] (4) |
i+2 |
Reads array[x] (6) |
Increments counts[4] (invalidates cache line) |
i+3 |
Increments counts[6] (invalidates cache line) |
Reads array[x] (2) |
i+4 |
Reads array[x] (3) |
Increments counts[2] (invalidates cache line) |
i+5 |
Increments counts[3] (invalidates cache line) |
… |
-
During time step i, Thread 0 reads the value at
array[x]in its part of the array, which is a 1 in this example. -
During time steps i + 1 to i + 5, each thread reads a value from
array[x]. Note that each thread is looking at different components of the array. Not only that, each read ofarrayin our sample execution yields unique values (so no race conditions in this sample execution sequence!). After reading the value fromarray[x], each thread increments the associated value incounts. -
Recall that the
countsarray fits on a single cache line in our L1 cache. As a result, every write tocountsinvalidates the entire line in every other L1 cache. -
The end result is that, despite updating different memory locations in
counts, any cache line containingcountsis invalidated with every update tocounts!
The invalidation forces all L1 caches to update the line with a "valid" version from L2. The repeated invalidation and overwriting of lines from the L1 cache is an example of thrashing, where repeated conflicts in the cache cause a series of misses.
The addition of more cores makes the problem worse, given that now more L1 caches
are invalidating the line. As a result, adding additional threads slows down
the runtime, despite the fact that each thread is accessing different elements
of the counts array! This is an example of false sharing, or the
illusion that individual elements are being shared by multiple cores. In the
previous example, it appears that all the cores are accessing the same elements of
counts, even though this is not the case.
14.5.3. Fixing False Sharing
One way to fix an instance of false sharing is to pad the array (in our case
counts) with additional elements so that it doesn’t fit in a single cache
line. However, padding can waste memory, and may not eliminate the problem from
all architectures (consider the scenario in which two different machines have
different L1 cache sizes). In most cases, writing code to support different
cache sizes is generally not worth the gain in performance.
A better solution is to have threads write to local storage whenever possible.
Local storage in this context refers to memory that is local to a thread.
The following solution reduces false sharing by choosing to perform updates to
a locally declared version of counts called local_counts.
Let’s revisit the final version of our countElems function (reproduced from
countElems_p_v3.c):
/*parallel version of CountSort algorithm step 1 (final attempt with mutexes):
* extracts arguments from args value
* calculates the portion of the array this thread is responsible for counting
* computes the frequency of all the elements in assigned component and stores
* the associated counts of each element in counts array
*/
void *countElems( void *args ){
//extract arguments
//omitted for brevity
int *array = myargs->ap;
long *counts = myargs->countp;
long local_counts[MAX] = {0}; //local declaration of counts array
//assign work to the thread
//compute chunk, start, and end values (omitted for brevity)
long i;
//heart of the program
for (i = start; i < end; i++){
val = array[i];
local_counts[val] = local_counts[val] + 1; //update local counts array
}
//update to global counts array
pthread_mutex_lock(&mutex); //acquire the mutex lock
for (i = 0; i < MAX; i++){
counts[i] += local_counts[i];
}
pthread_mutex_unlock(&mutex); //release the mutex lock
return NULL;
}The use of local_counts to accumulate frequencies in lieu of counts is
the major source of reduction of false sharing in this example:
for (i = start; i < end; i++){
val = array[i];
local_counts[val] = local_counts[val] + 1; //updates local counts array
}Since cache coherence is meant to maintain a consistent view of shared memory,
the invalidations trigger only on writes to shared values in memory. Since
local_counts is not shared among the different threads, a write to it will
not invalidate its associated cache line.
In the last component of the code, the mutex enforces correctness by ensuring
that only one thread updates the shared counts array at a time:
//update to global counts array
pthread_mutex_lock(&mutex); //acquire the mutex lock
for (i = 0; i < MAX; i++){
counts[i] += local_counts[i];
}
pthread_mutex_unlock(&mutex); //release the mutex lockSince counts is located on a single cache line, it will still get
invalidated with every write. The difference is that the
penalty here is at most MAX × t writes vs. n writes, where n is the
length of our input array, and t is the number of threads employed.