15.1. Heterogeneous Computing: Hardware Accelerators, GPGPU Computing, and CUDA
Heterogeneous computing is computing using multiple, different processing units found in a computer. These processing units often have different ISAs, some managed by the OS, and others not. Typically, heterogeneous computing means support for parallel computing using the computer’s CPU cores and one or more of its accelerator units such as graphics processing units (GPUs) or field programmable gate arrays (FPGAs)1.
It is increasingly common for developers to implement heterogeneous computing solutions to large, data-intensive and computation-intensive problems. These types of problems are pervasive in scientific computing, as well as in a more diverse range of applications to Big Data processing, analysis, and information extraction. By making use of the processing capabilities of both the CPU and the accelerator units that are available on a computer, a programmer can increase the degree of parallel execution in their application, resulting in improved performance and scalability.
In this section, we introduce heterogeneous computing using hardware accelerators to support general-purpose parallel computing. We focus on GPUs and the CUDA programming language.
15.1.1. Hardware Accelerators
In addition to the CPU, computers have other processing units that are designed to perform specific tasks. These units are not general-purpose processing units like the CPU, but are special-purpose hardware that is optimized to implement functionality that is specific to certain devices or that is used to perform specialized types of processing in the system. FPGAs, Cell processors, and GPUs are three examples of these types of processing units.
FPGAs
An FPGA is an integrated circuit that consists of gates, memory, and interconnection components. They are reprogrammable, meaning that they can be reconfigured to implement specific functionality in hardware, and they are often used to prototype application-specific integrated circuits (ASICs). FPGAs typically require less power to run than a full CPU, resulting in energy-efficient operation. Some example ways in which FPGAs are integrated into a computer system include as device controllers, for sensor data processing, for cryptography, and for testing new hardware designs (because they are reprogrammable, designs can be implemented, debugged, and tested on an FPGA). FPGAs can be designed as a circuit with a high number of simple processing units. FPGAs are also low-latency devices that can be directly connected to system buses. As a result, they have been used to implement very fast parallel computation that consists of regular patterns of independent parallel processing on several data input channels. However, reprogramming FPGAs takes a long time, and their use is limited to supporting fast execution of specific parts of parallel workloads or for running a fixed program workload2.
GPUs and Cell Processors
A Cell processor is a multicore processor consisting of one general-purpose processor and multiple co-processors that are specialized to accelerate a specific type of computation, such as multimedia processing. The Sony PlayStation 3 gaming system was the first Cell architecture, using the Cell coprocessors for fast graphics.
GPUs perform computer graphics computations — they operate on image data to enable high-speed graphics rendering and image processing. A GPU writes its results to a frame buffer, which delivers the data to the computer’s display. Driven by computer gaming applications, today sophisticated GPUs come standard in desktop and laptop systems.
In the mid 2000s, parallel computing researchers recognized the potential of using accelerators in combination with a computer’s CPU cores to support general-purpose parallel computing.
15.1.2. GPU architecture overview
GPU hardware is designed for computer graphics and image processing. Historically, GPU development has been driven by the video game industry. To support more detailed graphics and faster frame rendering, a GPU device consists of thousands of special-purpose processors, specifically designed to efficiently manipulate image data, such as the individual pixel values of a two-dimensional image, in parallel.
The hardware execution model implemented by GPUs is single instruction/multiple thread (SIMT), a variation of SIMD. SIMT is like multithreaded SIMD, where a single instruction is executed in lockstep by multiple threads running on the processing units. In SIMT, the total number of threads can be larger than the total number of processing units, requiring the scheduling of multiple groups of threads on the processors to execute the same sequence of instructions.
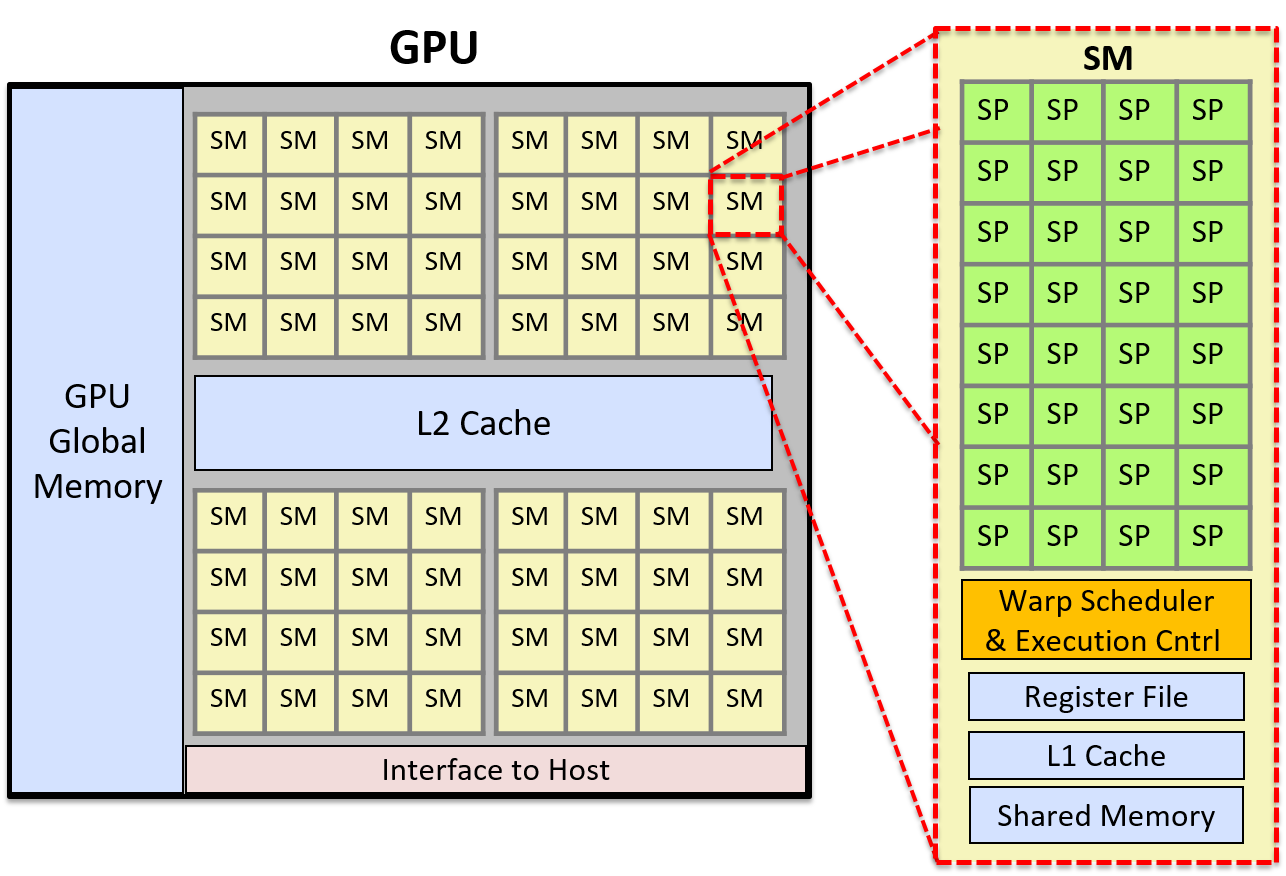
As an example, NVIDIA GPUs consist of several streaming multiprocessors (SMs), each of which has its own execution control units and memory space (registers, L1 cache, and shared memory). Each SM consists of several scalar processor (SP) cores. The SM includes a warp scheduler that schedules warps, or sets of application threads, to execute in lockstep on its SP cores. In lockstep execution, each thread in a warp executes the same instruction each cycle but on different data. For example, if an application is changing a color image to grayscale, each thread in a warp executes the same sequence of instructions at the same time to set a pixel’s RGB value to its grayscale equivalent. Each thread in the warp executes these instructions on a different pixel data value, resulting in multiple pixels of the image being updated in parallel. Because the threads are executed in lockstep, the processor design can be simplified so that multiple cores share the same instruction control units. Each unit contains cache memory and multiple registers that it uses to hold data as it’s manipulated in lockstep by the parallel processing cores.
Figure 1 shows a simplified GPU architecture that includes a detailed view of one of its SM units. Each SM consists of multiple SP cores, a warp scheduler, an execution control unit, an L1 cache, and shared memory space.
15.1.3. GPGPU Computing
General Purpose GPU (GPGPU) computing applies special-purpose GPU processors to general-purpose parallel computing tasks. GPGPU computing combines computation on the host CPU cores with SIMT computation on the GPU processors. GPGPU computing performs best on parallel applications (or parts of applications) that can be constructed as a stream processing computation on a grid of multidimensional data.
The host operating system does not manage the GPU’s processors or memory. As a result, space for program data needs to be allocated on the GPU and the data copied between the host memory and the GPU memory by the programmer. GPGPU programming languages and libraries typically provide programming interfaces to GPU memory that hide some or all of the difficulty of explicitly managing GPU memory from the programmer. For example, in CUDA a programmer can include calls to CUDA library functions to explicitly allocate CUDA memory on the GPU and to copy data between CUDA memory on the GPU and host memory. A CUDA programmer can also use CUDA unified memory, which is CUDA’s abstraction of a single memory space on top of host and GPU memory. CUDA unified memory hides the separate GPU and host memory, and the memory copies between the two, from the CUDA programmer.
GPUs also provide limited support for thread synchronization, which means that GPGPU parallel computing performs particularly well for parallel applications that are either embarrassingly parallel or have large extents of independent parallel stream-based computation with very few synchronization points. GPUs are massively parallel processors, and any program that performs long sequences of independent identical (or mostly identical) computation steps on data may perform well as a GPGPU parallel application. GPGPU computing also performs well when there are few memory copies between host and device memory. If GPU-CPU data transfer dominates execution time, or if an application requires fine-grained synchronization, GPGPU computing may not perform well or provide much, if any, gain over a multithreaded CPU version of the program.
15.1.4. CUDA
CUDA (Compute Unified Device Architecture)3 is NVIDIA’s programming interface
for GPGPU computing on its graphics devices.
CUDA is designed for heterogeneous computing in which some program functions
run on the host CPU, and others run on the GPU device. Programmers
typically write CUDA programs in C or C++ with annotations that specify
CUDA kernel functions, and they make calls to CUDA library functions to manage
GPU device memory. A CUDA kernel function is a function that is
executed on the GPU, and a CUDA thread is the basic unit of execution
in a CUDA program. CUDA threads are scheduled in warps that execute in
lockstep on the GPU’s SMs,
executing CUDA kernel code on their part of data stored in GPU memory.
Kernel functions are annotated with global to
distinguish them from host functions. CUDA device functions
are helper functions that can be called from a CUDA kernel function.
The memory space of a CUDA program is separated into host and GPU memory. The program must explicitly allocate and free GPU memory space to store program data manipulated by CUDA kernels. The CUDA programmer must either explicitly copy data to and from the host and GPU memory, or use CUDA unified memory that presents a view of memory space that is directly shared by the GPU and host. Here is an example of CUDA’s basic memory allocation, memory deallocation, and explicit memory copy functions:
/* "returns" through pass-by-pointer param dev_ptr GPU memory of size bytes
* returns cudaSuccess or a cudaError value on error
*/
cudaMalloc(void **dev_ptr, size_t size);
/* free GPU memory
* returns cudaSuccess or cudaErrorInvalidValue on error
*/
cudaFree(void *data);
/* copies data from src to dst, direction is based on value of kind
* kind: cudaMemcpyHosttoDevice is copy from cpu to gpu memory
* kind: cudaMemcpyDevicetoHost is copy from gpu to cpu memory
* returns cudaSuccess or a cudaError value on error
*/
cudaMemcpy(void *dst, const void *src, size_t count, cudaMemcpyKind kind);CUDA threads are organized into blocks, and the blocks are organized into a grid. Grids can be organized into one-, two-, or three-dimensional groupings of blocks. Blocks, likewise, can be organized into one-, two-, or three-dimensional groupings of threads. Each thread is uniquely identified by its thread (x,y,z) position in its containing block’s (x,y,z) position in the grid. For example, a programmer could define two-dimensional block and grid dimensions as the following:
dim3 blockDim(16,16); // 256 threads per block, in a 16x16 2D arrangement
dim3 gridDim(20,20); // 400 blocks per grid, in a 20x20 2D arrangementWhen a kernel is invoked, its blocks/grid and thread/block layout is specified
in the call. For example, here is a call to a kernel function named
do_something specifying the grid and block layout using gridDim and
blockDim defined above (and passing parameters dev_array and 100):
ret = do_something<<<gridDim,blockDim>>>(dev_array, 100);Figure 2 shows an example of a two-dimensional arrangement of thread blocks. In this example, the grid is a 3 × 2 array of blocks, and each block is a 4 × 3 array of threads.
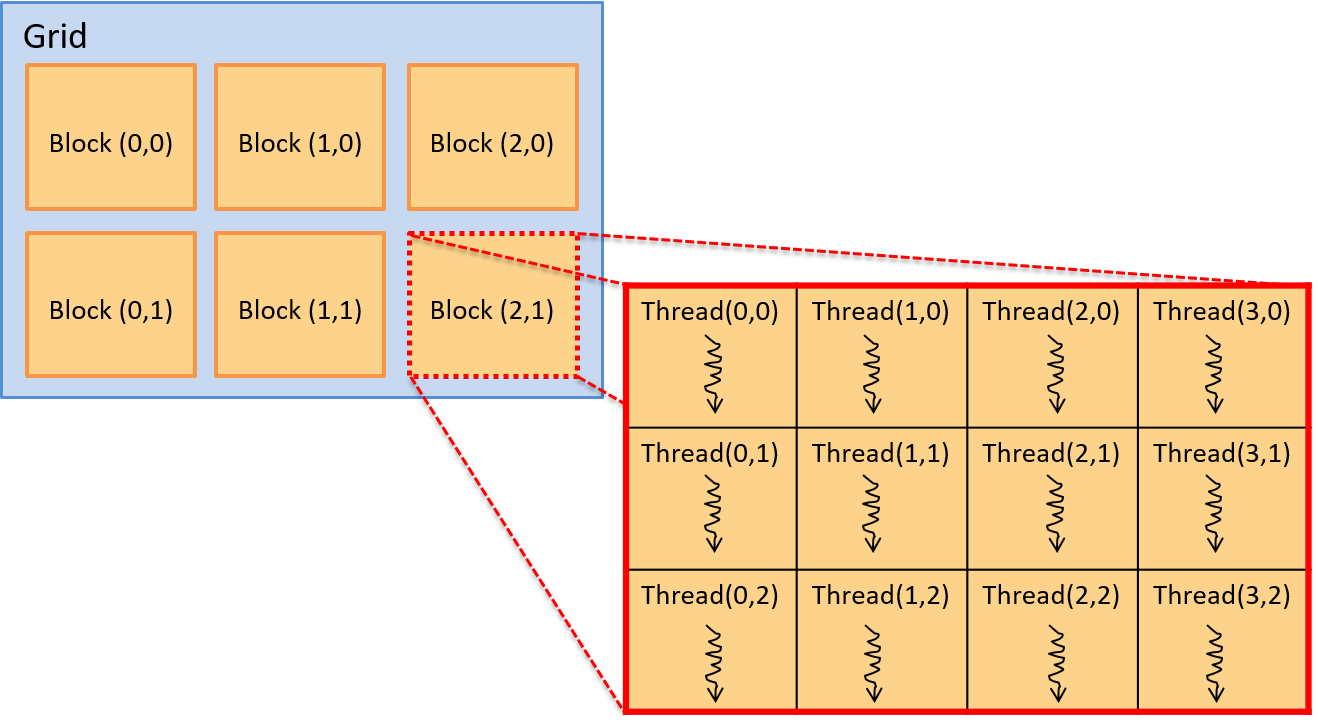
A thread’s position in this layout is given by the (x,y) coordinate in its
containing block (threadId.x, threadId.y) and by the (x,y) coordinate of its
block in the grid (blockIdx.x, blockIdx.y). Note that block and thread
coordinates are (x,y) based, with the x-axis being horizontal, and the y-axis
vertical. The (0,0) element is in the upper left. The CUDA kernel also has
variables that are defined to the block dimensions (blockDim.x and
blockDim.y). Thus, for any thread executing the kernel, its (row, col)
position in the two-dimensional array of threads in the two-dimensional array
of blocks can be logically identified as follows:
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;Although not strictly necessary, CUDA programmers often organize blocks and threads to match the logical organization of program data. For example, if a program is manipulating a two-dimensional matrix, it often makes sense to organize threads and blocks into a two-dimensional arrangement. This way, a thread’s block (x,y) and its thread (x,y) within a block can be used to associate a thread’s position in the two-dimensional blocks of threads with one or more data values in the two-dimensional array.
Example CUDA Program: Scalar Multiply
As an example, consider a CUDA program that performs scalar multiplication of a vector:
x = a * x // where x is a vector and a is a scalar valueBecause the program data comprises one-dimensional arrays, using a one-dimensional layout of blocks/grid and threads/block works well. This is not necessary, but it makes the mapping of threads to data easier.
When run, the main function of this program will do the following:
-
Allocate host-side memory for the vector
xand initialize it. -
Allocate device-side memory for the vector
xand copy it from host memory to GPU memory. -
Invoke a CUDA kernel function to perform vector scalar multiply in parallel, passing as arguments the device address of the vector
xand the scalar valuea. -
Copy the result from GPU memory to host memory vector
x.
In the example that follows, we show a CUDA program that performs these steps to implement scalar vector multiplication. We have removed some error handling and details from the code listing, but the full solution is available here: scalar_multiply_cuda.cu.
The main function of the CUDA3 program performs the four steps listed above:
#include <cuda.h>
#define BLOCK_SIZE 64 /* threads per block */
#define N 10240 /* vector size */
// some host-side init function
void init_array(int *vector, int size, int step);
// host-side function: main
int main(int argc, char **argv) {
int *vector, *dev_vector, scalar;
scalar = 3; // init scalar to some default value
if(argc == 2) { // get scalar's value from a command line argument
scalar = atoi(argv[1]);
}
// 1. allocate host memory space for the vector (missing error handling)
vector = (int *)malloc(sizeof(int)*N);
// initialize vector in host memory
// (a user-defined initialization function not listed here)
init_array(vector, N, 7);
// 2. allocate GPU device memory for vector (missing error handling)
cudaMalloc(&dev_vector, sizeof(int)*N);
// 2. copy host vector to device memory (missing error handling)
cudaMemcpy(dev_vector, vector, sizeof(int)*N, cudaMemcpyHostToDevice);
// 3. call the CUDA scalar_multiply kernel
// specify the 1D layout for blocks/grid (N/BLOCK_SIZE)
// and the 1D layout for threads/block (BLOCK_SIZE)
scalar_multiply<<<(N/BLOCK_SIZE), BLOCK_SIZE>>>(dev_vector, scalar);
// 4. copy device vector to host memory (missing error handling)
cudaMemcpy(vector, dev_vector, sizeof(int)*N, cudaMemcpyDeviceToHost);
// ...(do something on the host with the result copied into vector)
// free allocated memory space on host and GPU
cudaFree(dev_vector);
free(vector);
return 0;
}Each CUDA thread executes the CUDA kernel function scalar_multiply.
A CUDA kernel function is written from an individual thread’s point
of view. It typically consists of two main steps: (1) the calling
thread determines which portion of the data it is responsible for
based on its thread’s position in its enclosing block and its block’s
position in the grid; (2) and the calling thread
performs application-specific computation on its portion of the data.
In this example, each
thread is responsible for computing scalar multiplication on exactly
one element in the array. The kernel function code first calculates
a unique index value based on the calling thread’s
block and thread identifier. It then uses this value as an index
into the array of data to perform scalar multiplication on its
array element (array[index] = array[index] * scalar).
CUDA threads running on the GPU’s SM units each compute a
different index value to update array elements in parallel.
/*
* CUDA kernel function that performs scalar multiply
* of a vector on the GPU device
*
* This assumes that there are enough threads to associate
* each array[i] element with a signal thread
* (in general, each thread would be responsible for a set of data elements)
*/
__global__ void scalar_multiply(int *array, int scalar) {
int index;
// compute the calling thread's index value based on
// its position in the enclosing block and grid
index = blockIdx.x * blockDim.x + threadIdx.x;
// the thread's uses its index value is to
// perform scalar multiply on its array element
array[index] = array[index] * scalar;
}CUDA Thread Scheduling and Synchronization
Each CUDA thread block is run by a GPU SM unit. An SM schedules a warp of threads from the same thread block to run its processor cores. All threads in a warp execute the same set of instructions in lockstep, typically on different data. Threads share the instruction pipeline but get their own registers and stack space for local variables and parameters.
Because blocks of threads are scheduled on individual SMs, increasing the threads per block increases the degree of parallel execution. Because the SM schedules thread warps to run on its processing units, if the number of threads per block is a multiple of the warp size, no SM processor cores are wasted in the computation. In practice, using a number of threads per block that is a small multiple of the number of processing cores of an SM works well.
CUDA guarantees that all threads from a single kernel call complete before any threads from a subsequent kernel call are scheduled. Thus, there is an implicit synchronization point between separate kernel calls. Within a single kernel call, however, thread blocks are scheduled to run the kernel code in any order on the GPU SMs. As a result, a programmer should not assume any ordering of execution between threads in different thread blocks. CUDA provides some support for synchronizing threads, but only for threads that are in the same thread block.
15.1.5. Other Languages for GPGPU Programming
There are other programming languages for GPGPU computing. OpenCL, OpenACC, and OpenHMPP are three examples of languages that can be used to program any graphics device (they are not specific to NVIDIA devices). OpenCL (Open Computing Language) has a similar programming model to CUDA’s; both implement a lower-level programming model (or implement a thinner programming abstraction) on top of the target architectures. OpenCL targets a wide range of heterogeneous computing platforms that include a host CPU combined with other compute units, which could include CPUs or accelerators such as GPUs and FPGAs. OpenACC (Open Accelerator) is a higher-level abstraction programming model than CUDA or OpenCL. It is designed for portability and programmer ease. A programmer annotates portions of their code for parallel execution, and the compiler generates parallel code that can run on GPUs. OpenHMPP (Open Hybrid Multicore Programming) is another language that provides a higher-level programming abstraction for heterogeneous programming.
15.1.6. References
-
"A Survey Of Techniques for Architecting and Managing Asymmetric Multicore Processors", Sparsh Mittal, in ACM Computing Surveys 48(3), February 2016
-
"FPGAs and the Road to Reprogrammable HPC", inside HPC, July 2019 (https://insidehpc.com/2019/07/fpgas-and-the-road-to-reprogrammable-hpc/)
-
CUDA Toolkit documentation: https://docs.nvidia.com/cuda/index.html
-
"GPU Programming", from CSinParallel: https://csinparallel.org/csinparallel/modules/gpu_programming.html, and CSinParallel has other GPU programming modules: https://csinparallel.org