14.1. Programming Multicore Systems
Most of the common languages that programmers know today were created prior to the multicore age. As a result, many languages cannot implicitly (or automatically) employ multicore processors to speed up the execution of a program. Instead, programmers must specifically write software to leverage the multiple cores on a system.
14.1.1. The Impact of Multicore Systems on Process Execution
Recall that a process can be thought of as an abstraction of a running program. Each process executes in its own virtual address space. The operating system (OS) schedules processes for execution on the CPU; a context switch occurs when the CPU changes which process it currently executes.
Figure 1 illustrates how five example processes may execute on a single-core CPU.
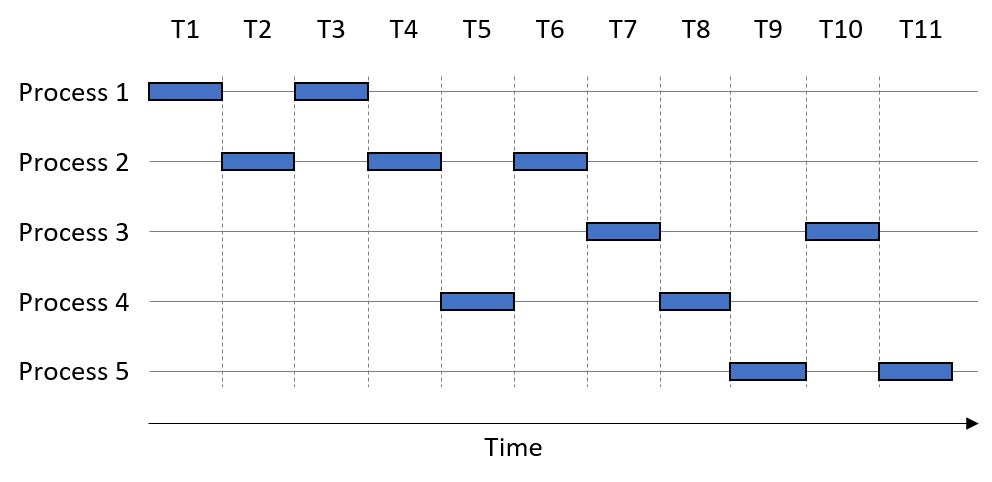
The horizontal axis is time, with each time slice taking one unit of time. A box indicates when a process is using the single-core CPU. Assume that each process executes for one full time slice before a context switch occurs. So, Process 1 uses the CPU during time steps T1 and T3.
In this example, the order of process execution is P1, P2, P1, P2, P4, P2, P3, P4, P5, P3, P5. We take a moment here to distinguish between two measures of time. The CPU time measures the amount of time a process takes to execute on a CPU. In contrast, the wall-clock time measures the amount of time a human perceives a process takes to complete. The wall-clock time is often significantly longer than the CPU time, due to context switches. For example, Process 1’s CPU time requires two time units, whereas its wall-clock time is three time units.
When the total execution time of one process overlaps with another, the processes are running concurrently with each other. Operating systems employed concurrency in the single-core era to give the illusion that a computer can execute many things at once (e.g., you can have a calculator program, a web browser, and a word processing document all open at the same time). In truth, each process executes serially and the operating system determines the order in which processes execute and complete (which often differs in subsequent runs).
Returning to the example, observe that Process 1 and Process 2 run concurrently with each other, since their executions overlap at time points T2-T4. Likewise, Process 2 runs concurrently with Process 4, as their executions overlap at time points T4-T6. In contrast, Process 2 does not run concurrently with Process 3, because they share no overlap in their execution; Process 3 only starts running at time T7, whereas Process 2 completes at time T6.
A multicore CPU enables the OS to schedule a different process to each available core, allowing processes to execute simultaneously. The simultaneous execution of instructions from processes running on multiple cores is referred to as parallel execution. Figure 2 shows how our example processes might execute on a dual-core system.
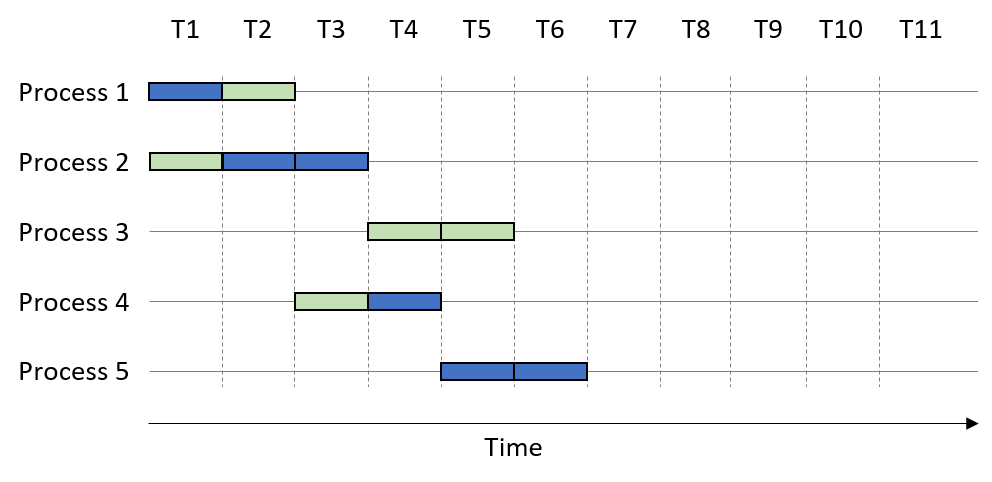
In this example, the two CPU cores are colored differently. Suppose that the process execution order is again P1, P2, P1, P2, P4, P2, P3, P4, P5, P3, P5. The presence of multiple cores enables certain processes to execute sooner. For example, during time unit T1, the first core executes Process 1 while the second core executes Process 2. At time T2, the first core executes Process 2 while the second executes Process 1. Thus, Process 1 finishes executing after time T2, whereas Process 2 finishes executing at time T3.
Note that the parallel execution of multiple processes increases just the number of processes that execute at any one time. In Figure 2, all the processes complete execution by time unit T7. However, each individual process still requires the same amount of CPU time to complete as shown in Figure 1. For example, Process 2 requires three time units regardless of execution on a single or multicore system (i.e., its CPU time remains the same). A multicore processor increases the throughput of process execution, or the number of processes that can complete in a given period of time. Thus, while the CPU time of an individual process remains unchanged, its wall-clock time may decrease.
14.1.2. Expediting Process Execution with Threads
One way to speed up the execution of a single process is to decompose it into lightweight, independent execution flows called threads. Figure 3 shows how a process’s virtual address space changes when it is multithreaded with two threads. While each thread has its own private allocation of call stack memory, all threads share the program data, instructions, and the heap allocated to the multithreaded process.
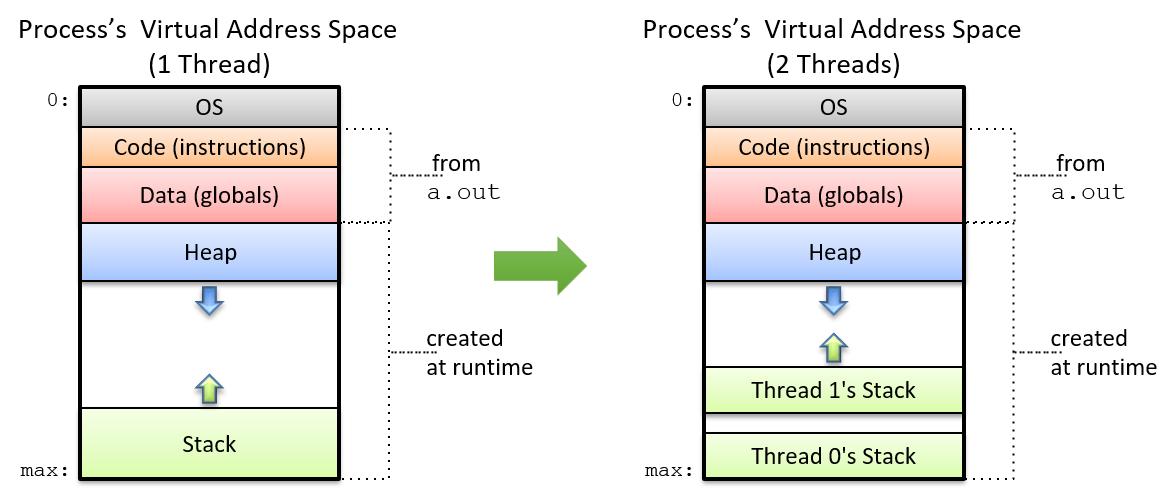
The operating system schedules threads in the same manner as it schedules processes. On a multicore processor, the OS can speed up the execution of a multithreaded program by scheduling the different threads to run on separate cores. The maximum number of threads that can execute in parallel is equal to the number of physical cores on the system. If the number of threads exceeds the number of physical cores, the remaining threads must wait their turn to execute (similar to how processes execute on a single core).
An Example: Scalar Multiplication
As an initial example of how to use multithreading to speed up an application,
consider the problem of performing scalar multiplication of an array array
and some integer s. In scalar multiplication, each element in the array is
scaled by multiplying the element with s.
A serial implementation of a scalar multiplication function follows:
void scalar_multiply(int * array, long length, int s) {
int i;
for (i = 0; i < length; i++) {
array[i] = array[i] * s;
}
}Suppose that array has N total elements. To create a multithreaded version
of this application with t threads, it is necessary to:
-
Create t threads.
-
Assign each thread a subset of the input array (i.e., N/t elements).
-
Instruct each thread to multiply the elements in its array subset by
s.
Suppose that the serial implementation of scalar_multiply spends 60 seconds
multiplying an input array of 100 million elements. To build a version that
executes with t= 4 threads, we assign each thread one fourth of the total input
array (25 million elements).
Figure 4 shows what happens when we run four threads on a single core. As before, the execution order is left to the operating system. In this scenario, assume that the thread execution order is Thread 1, Thread 3, Thread 2, Thread 4. On a single-core processor (represented by the squares), each thread executes sequentially. Thus, the multithreaded process running on one core will still take 60 seconds to run (perhaps a little longer, given the overhead of creating threads).
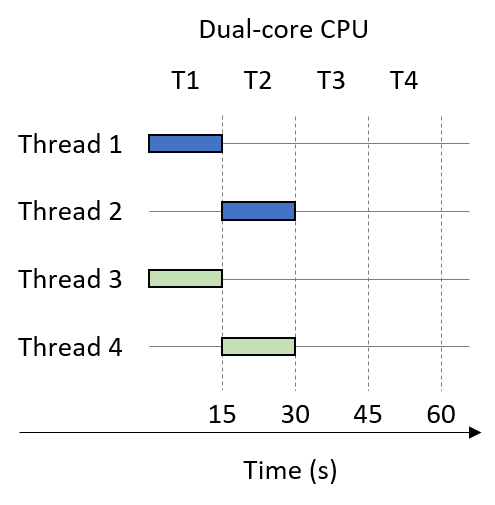
Now suppose that we run our multithreaded process on a dual-core system. Figure 5 shows the result. Again, assume t = 4 threads, and that the thread execution order is Thread 1, Thread 3, Thread 2, Thread 4. Our two cores are represented by shaded squares. Since the system is dual-core, Thread 1 and Thread 3 execute in parallel during time step T1. Threads 2 and 4 then execute in parallel during time step T2. Thus, the multithreaded process that originally took 60 seconds to run now runs in 30 seconds.
Finally, suppose that the multithreaded process (t = 4) is run on a quad-core CPU. Figure 6 shows one such execution sequence. Each of the four cores in Figure 6 is shaded differently. On the quad-core system, each thread executes in parallel during time slice T1. Thus, on a quad-core CPU, the multithreaded process that originally took 60 seconds now runs in 15 seconds.
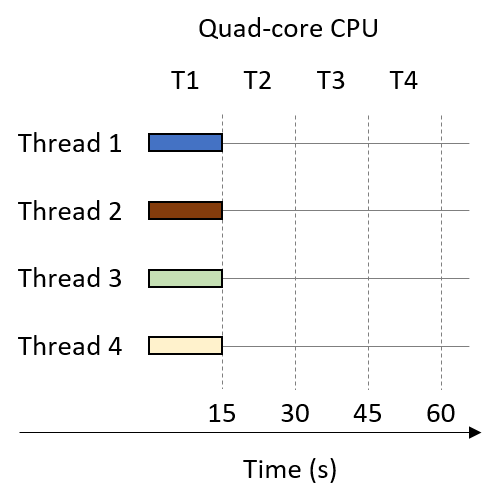
In general, if the number of threads matches the number of cores (c) and the operating system schedules each thread to run on a separate core in parallel, then the multithreaded process should run in approximately 1/c of the time. Such linear speedup is ideal, but not frequently observed in practice. For example, if there are many other processes (or multithreaded processes) waiting to use the CPU, they will all compete for the limited number of cores, resulting in resource contention among the processes. If the number of specified threads exceeds the number of CPU cores, each thread must wait its turn to run. We explore other factors that often prevent linear speedup later in this chapter.