13.2. Processes
One of the main abstractions implemented by the operating system is a process. A process represents an instance of a program running in the system, which includes the program’s binary executable code, data, and execution context. The context tracks the program’s execution by maintaining its register values, stack location, and the instruction it is currently executing.
Processes are necessary abstractions in multiprogramming systems, which support multiple processes existing in the system at the same time. The process abstraction is used by the OS to keep track of individual instances of programs running in the system, and to manage their use of system resources.
The OS provides each process with a "lone view" abstraction of the system. That is, the OS isolates processes from one another and gives each process the illusion that it’s controlling the entire machine. In reality, the OS supports many active processes and manages resource sharing among them. The OS hides the details of sharing and accessing system resources from the user, and the OS protects processes from the actions of other processes running in the system.
For example, a user may simultaneously run two instances of a Unix shell program along with a web browser on a computer system. The OS creates three processes associated with these three running programs: one process for each separate execution of the Unix shell program, and one process for the web browser. The OS handles switching between these three processes running on the CPU, and it ensures that as a process runs on the CPU, only the execution state and system resources allocated to the process can be accessed.
13.2.1. Multiprogramming and Context Switching
Multiprogramming enables the OS to make efficient use of hardware resources. For example, when a process running on the CPU needs to access data that are currently on disk, rather than have the CPU sit idle waiting for the data to be read into memory, the OS can give the CPU to another process and let it run while the read operation for the original process is being handled by the disk. By using multiprogramming, the OS can mitigate some of the effects of the memory hierarchy on its program workload by keeping the CPU busy executing some processes while other processes are waiting to access data in the lower levels of the memory hierarchy.
General-purpose operating systems often implement timesharing, which is multiprogramming wherein the OS schedules each process to take turns executing on the CPU for short time durations (known as a time slice or quantum). When a process completes its time slice on the CPU, the OS removes the process from the CPU and lets another run. Most systems define time slices to be a few milliseconds (10-3 seconds), which is a long time in terms of CPU cycles but is not noticeable to a human.
Timesharing systems further support the "lone view" of the computer system to
the user; because each process frequently executes on the CPU for short bursts
of time, the fact that they are all sharing the CPU is usually imperceptible
to the user. Only when the system is very heavily loaded might a user notice
the effects of other processes in the system. The Unix command ps -A lists
all the processes running in the system — you may be surprised by how many
there are. The top command is also useful for seeing the
state of the system as it runs by displaying the set of processes that
currently use the most system resources (such as CPU time and memory
space).
In multiprogrammed and timeshared systems, processes run concurrently, meaning that their executions overlap in time. For example, the OS may start running process A on the CPU, and then switch to running process B for a while, and later switch back to running process A some more. In this scenario, processes A and B run concurrently because their execution on the CPU overlaps due to the OS switching between the two.
Context Switching
The mechanism behind multiprogramming determines how the OS swaps one process running on the CPU with another. The policy aspect of multiprogramming governs scheduling the CPU, or picking which process from a set of candidate processes gets to use the CPU next and for how long. We focus primarily on the mechanism of implementing multiprogramming. Operating systems textbooks cover scheduling policies in more detail.
The OS performs context switching, or swapping process state on the CPU, as the primary mechanism behind multiprogramming (and timesharing). There are two main steps to performing a CPU context switch:
-
The OS saves the context of the current process running on the CPU, including all of its register values (PC, stack pointers, general-purpose register, condition codes, etc.), its memory state, and some other state (for example the state of system resources it uses, like open files).
-
The OS restores the saved context from another process on the CPU and starts the CPU running this other process, continuing its execution from the instruction where it left off.
One part of context switching that may seem impossible to accomplish is that the OS’s code that implements context switching must run on the CPU while it saves (restores) a process’s execution contexts from (to) the CPU; the instructions of the context switching code need to use CPU hardware registers to execute, but the register values from the process being context switched off the CPU need to be saved by the context switching code. Computer hardware provides some help to make this possible.
At boot time, the OS initialized the hardware, including initializing the CPU state, so that when the CPU switches to kernel mode on an interrupt, the OS interrupt handler code starts executing and the interrupted process’s execution state is protected from this execution. Together, the computer hardware and OS perform some of the initial saving of the user-level execution context, enough that the OS code can run on the CPU without losing the execution state of the interrupted process. For example, register values of the interrupted process need to be saved so that when the process runs again on the CPU, the process can continue from the point at which it left off, using its register values. Depending on the hardware support, saving the user-level process’s register values may be done entirely by the hardware or may be done almost entirely in software as the first part of the kernel’s interrupt handling code. At a minimum, the process’s program counter (PC) value needs to be saved so that its value is not lost when the kernel interrupt handler address is loaded into the PC.
Once the OS starts running, it executes its full process context switching code, saving the full execution state of the process running on the CPU and restoring the saved execution state of another process onto the CPU. Because the OS runs in kernel mode it is able to access any parts of computer memory and can execute privileged instructions and access any hardware registers. As a result, its context switching code is able to access and save the CPU execution state of any process to memory, and it is able to restore from memory the execution state of any process to the CPU. OS context switching code completes by setting up the CPU to execute the restored process’s execution state and by switching the CPU to user mode. Once switched to user mode, the CPU executes instructions, and uses execution state, from the process that the OS context switched onto the CPU.
13.2.2. Process State
In multiprogrammed systems, the OS must track and manage the multiple processes existing in the system at any given time. The OS maintains information about each process, including:
-
A process id (PID), which is a unique identifier for a process. The
pscommand lists information about processes in the system, including their PID values. -
The address space information for the process.
-
The execution state of the process (e.g., CPU register values, stack location).
-
The set of resources allocated to the process (e.g., open files).
-
The current process state, which is a value that determines its eligibility for execution on the CPU.
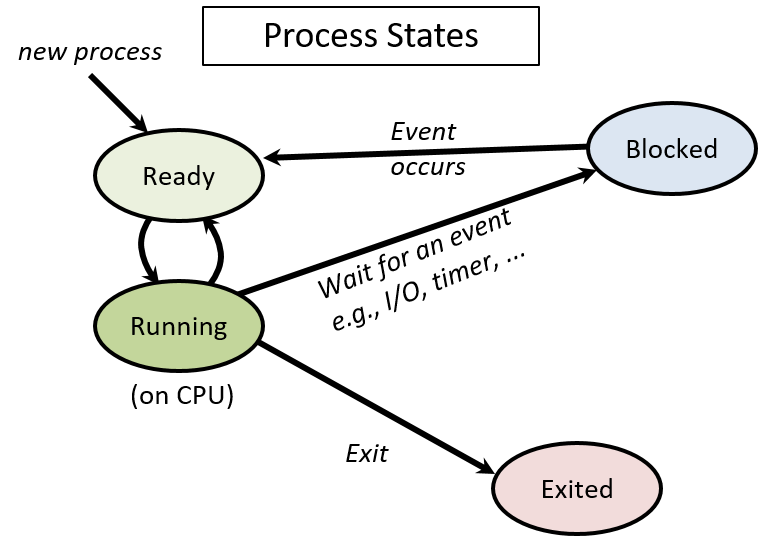
Over the course of its lifetime, a process moves through several states, which correspond to different categories of process execution eligibility. One way that the OS uses process state is to identify the set of processes that are candidates for being scheduled on the CPU.
The set of process execution states are:
-
Ready: The process could run on the CPU but is not currently scheduled (it is a candidate for being context switched on to the CPU). Once a new process is created and initialized by the OS, it enters the ready state (it is ready for the CPU to start executing its first instruction). In a timesharing system, if a process is context switched off the CPU because its time slice is up, it is also placed in the ready state (it is ready for the CPU to execute its next instruction, but it used up its time slice and has to wait its turn to get scheduled again on the CPU).
-
Running: The process is scheduled on the CPU and is actively executing instructions.
-
Blocked: The process is waiting for some event before it can continue being executed. For example, the process is waiting for some data to be read in from disk. Blocked processes are not candidates for being scheduled on the CPU. After the event on which the process is blocked occurs, the process moves to the ready state (it is ready to run again).
-
Exited: The process has exited but still needs to be completely removed from the system. A process exits due to its completing the execution of its program instructions, or by exiting with an error (e.g., it tries to divide by zero), or by receiving a termination request from another process. An exited process will never run again, but it remains in the system until final clean-up associated with its execution state is complete.
Figure 1 shows the lifetime of a process in the system, illustrating how it moves between different states. Note the transitions (arrows) from one state to another. For example, a process can enter the Ready state in one of three ways: first, if it is newly created by the OS; second, if it was blocked waiting for some event and the event occurs; and third, if it was running on the CPU and its time slice is over and the OS context switches it off to give another Ready process its turn on the CPU.
13.2.3. Creating (and Destroying) Processes
An OS creates a new process when an existing process makes a system
call requesting it to do so. In Unix, the fork system call creates
a new process. The
process calling fork is the parent process and the new
process it creates is its child process. For example, if you run a.out
in a shell, the shell process calls the fork system call to request that
the OS create a new child process that will be used to run the a.out program.
Another example is a web browser process that calls fork to create
child processes to handle different browsing events. A web browser may
create a child process to handle communication with a web server
when a user loads a web page. It may create another process to handle user
mouse input, and other processes to handle separate browser windows or tabs.
A multiple-process web browser like this is able to continue handling user
requests through some of its child browser processes, while at the same
time some of its other child browser processes may be blocked waiting for
remote web server responses or for user mouse clicks.
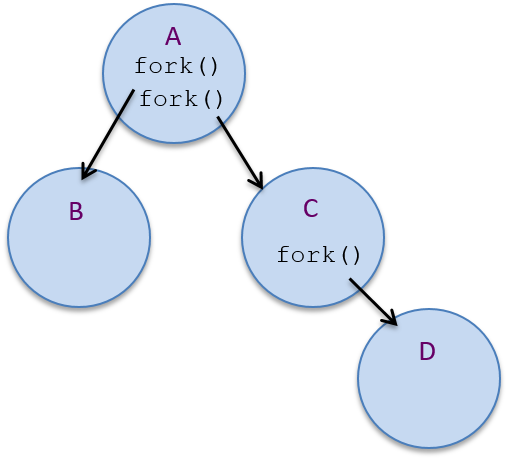
A process hierarchy of parent-child relationships exists between the set of
processes active in the system. For example, if process A makes two calls to
fork, two new child processes are created, B and C_. If process C
then calls fork, another new process, D, will be created. Process C is
the child of A, and the parent of D. Processes B and C are siblings
(they share a common parent process, process A). Process A is the
ancestor of B, C, and D. This example is illustrated in Figure 2.
pstree, or ps -Aef --forest.Since existing processes trigger process creation, a system needs at least one
process to create any new processes. At boot time, the OS creates the first
user-level process in the system. This special process, named init, sits
at the very top of the process hierarchy as the ancestor of all other
processes in the system.
fork
The fork system call is used to create a process. At the time of the fork,
the child inherits its execution state from its parent. The OS creates a
copy of the calling (parent) process’s execution state at the point when the
parent calls fork. This execution state includes the parent’s address space
contents, CPU register values, and any system resources it has allocated (e.g.,
open files). The OS also creates a new process control struct, an OS data
structure for managing the child process, and it assigns the child process a
unique PID. After the OS creates and initializes the new process, the child
and parent are concurrent — they both continue running and their executions
overlap as the OS context switches them on and off the CPU.
When the child process is first scheduled by the OS
to run on the CPU, it starts executing at the point
at which its parent left off — at the return from the fork call. This is
because fork gives the child a copy of its
parent’s execution state (the child executes using its
own copy of this state when it starts running). From the programmer’s
point of view, a call to fork returns twice: once in the context
of the running parent process, and once in the context of the running
child process.
In order to differentiate the child and parent processes in a program,
a call to fork returns different values to the parent and child.
The child process always receives a return value of 0, whereas the
parent receives the child’s PID value (or -1 if fork fails).
For example, the following code snippet shows a call to the fork
system call that creates a new child process of the calling process:
pid_t pid;
pid = fork(); /* create a new child process */
print("pid = %d\n", pid); /* both parent and child execute this */After the call to fork creates a new child process, the parent and child
processes both continue executing, in their separate execution contexts, at
the return point of the fork call. Both processes assign the return
value of fork to their pid variable and both call printf. The
child process’s call prints out 0 and the parent process prints out the
child’s PID value.
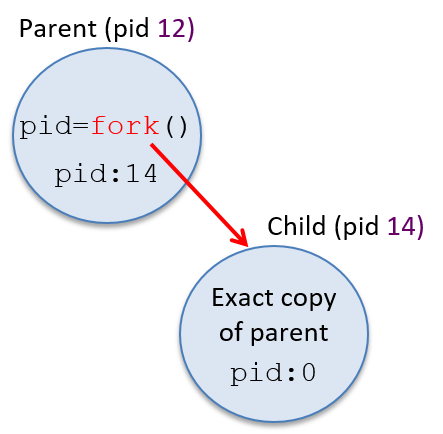
Figure 3 shows an example of what the process hierarchy looks like after
this code’s execution. The child process gets an exact copy of the parent
process’s execution context at the point of the fork, but the value
stored in its variable pid differs from its parent because fork returns
the child’s PID value (14 in this example) to the parent process, and
0 to the child.
Often, the programmer wants the child and parent processes to perform
different tasks after the fork call. A programmer can use the
different return values from fork to trigger the parent and
child processes to execute different code branches. For example, the
following code snippet creates a new child process and uses the return value
from fork to have the child and parent processes execute different code
branches after the call:
pid_t pid;
pid = fork(); /* create a new child process */
if (pid == 0) {
/* only the child process executes this code */
...
} else if (pid != -1) {
/* only the parent process executes this code */
...
}It is important to remember that as soon as they are created, the child and parent processes run concurrently in their own execution contexts, modifying their separate copies of program variables and possibly executing different branches in the code.
Consider the following program
that contains a call to fork with branching on the value of pid
to trigger the parent and child processes to execute different code
(this example also shows a call to getpid that returns the PID
of the calling process):
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(void) {
pid_t pid, mypid;
printf("A\n");
pid = fork(); /* create a new child process */
if(pid == -1) { /* check and handle error return value */
printf("fork failed!\n");
exit(pid);
}
if (pid == 0) { /* the child process */
mypid = getpid();
printf("Child: fork returned %d, my pid %d\n", pid, mypid);
} else { /* the parent process */
mypid = getpid();
printf("Parent: fork returned %d, my pid %d\n", pid, mypid);
}
printf("B:%d\n", mypid);
return 0;
}When run, this program’s output might look like the following (assume that the parent’s PID is 12 and the child’s is 14):
A
Parent: fork returned 14, my pid 12
B:12
Child: fork returned 0, my pid 14
B:14In fact, the program’s output could look like any of the possible options shown in Table 1 (and you will often see more than one possible ordering of output if you run the program multiple times). In Table 1, the parent prints B:12 and the child B:14 in this example, but the exact PID values will vary from run to run.
| Option 1 | Option 2 | Option 3 | Option 4 | Option 5 | Option 6 |
|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
These six different output orderings are possible because after the fork
system call returns, the parent and child processes are concurrent and can be
scheduled to run on the CPU in many different orderings, resulting in any
possible interleaving of their instruction sequences. Consider the execution
time line of this program, shown in Figure 4. The dotted line represents
concurrent execution of the two processes. Depending on when each is scheduled
to run on the CPU, one could execute both its printf statements before the
other, or the execution of their two printf statements could be interleaved,
resulting in any of the possible outcomes shown in the table above. Because
only one process, the parent, exists before the call to fork, A is always
printed by the parent before any of the output after the call to fork.
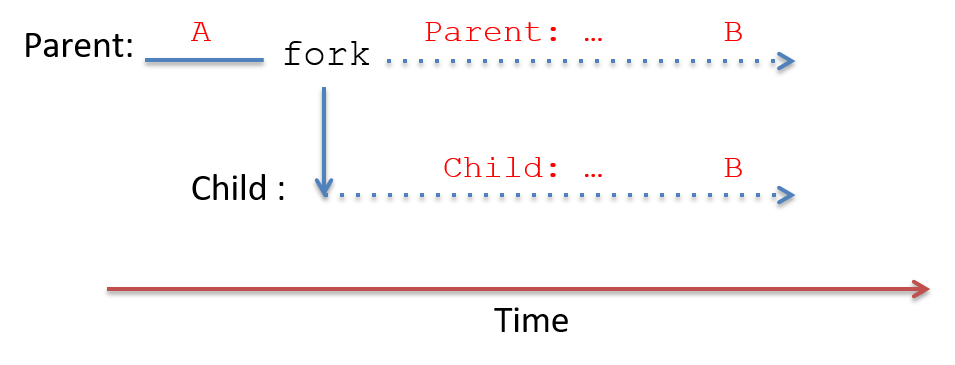
fork. After fork returns, both run concurrently (shown in the dotted lines).13.2.4. exec
Usually a new process is created to execute a program that is different from
that of its parent process. This means that fork is often called to create a
process with the intention of running a new program from its starting point
(that is starting its execution from its first instruction). For example, if a
user types ./a.out in a shell, the shell process forks a new child process to
run a.out. As two separate processes, the shell and the a.out process are
protected from each other; they cannot interfere with each other’s execution
state.
While fork creates the new child process, it does not cause the
child to run a.out. To initialize the child process to run a new program,
the child process calls one of the exec system calls. Unix provides
a family of exec system calls that trigger the OS to overlay the
calling process’s image with a new image from a binary executable
file. In other words, an exec system call tells the OS to overwrite
the calling process’s address space contents with the specified
a.out and to reinitialize its execution state to start
executing the very first instruction in the a.out program.
One example of an exec system call is execvp, whose function prototype is
as follows:
int execvp(char *filename, char *argv[]);The filename parameter specifies the name of a binary executable program to
initialize the process’s image, and argv contains the command line arguments
to pass into the main function of the program when it starts
executing.
Here’s an example code snippet that, when executed, creates
a new child process to run a.out:
pid_t pid;
int ret;
char *argv[2];
argv[0] = "a.out"; // initialize command line arguments for main
argv[1] = NULL;
pid = fork();
if (pid == 0) { /* child process */
ret = execvp("a.out", argv);
if (ret < 0) {
printf("Error: execvp returned!!!\n");
exit(ret);
}
}The argv variable is initialized to the value of the argv argument that
is passed to the main function of a.out:
int main(int argc, char *argv) { ...execvp will figure out the value to pass to argc based on this argv
value (in this case 1).
Figure 5 shows what the process hierarchy would look like after executing this code:
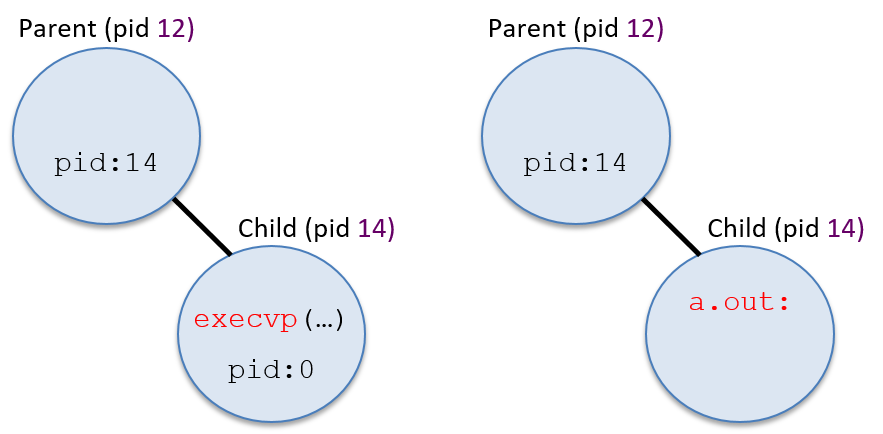
Something to note in the example code shown above is its seemingly odd error
message after the call to execvp: why would returning from an exec system
call be an error? If the exec system call is successful, then the error
detection and handling code immediately following it will never be executed
because the process will now be executing code in the a.out program instead
of this code (the process’s address space contents have been changed by exec).
That is, when a call to an exec function is successful, the process doesn’t
continue its execution at the return of the exec call. Because of this
behavior, the following code snippet is equivalent to the one shown above
(however, the one above is typically easier to understand):
pid_t pid;
int ret;
pid = fork();
if (pid == 0) { /* child process */
ret = execvp("a.out", argv);
printf("Error: execvp returned!!!\n"); /* only executed if execvp fails */
exit(ret);
}13.2.5. exit and wait
To terminate, a process calls the exit system call, which triggers the OS to
clean up most of the process’s state. After running the exit code, a process
notifies its parent process that it has exited. The parent is responsible for
cleaning up the exited child’s remaining state from the system.
Processes can be triggered to exit in several ways. First, a process
may complete all of its application code. Returning from its main
function leads to a process invoking the exit system call. Second,
a process can perform an invalid action, such as dividing by zero or
dereferencing a null pointer, that results in its exiting. Finally, a
process can receive a signal from the OS or another process, telling
it to exit (in fact, dividing by zero and NULL pointer dereferences
result in the OS sending the process SIGFPE and SIGSEGV signals telling
it to exit).
If a shell process wants to terminate its child process running a.out, it can
send the child a SIGKILL signal. When the child process receives the signal,
it runs signal handler code for SIGKILL that calls exit, terminating the
child process. If a user types CTRL-C in a Unix shell that is currently
running a program, the child process receives a SIGINT signal. The default
signal handler for SIGINT also calls exit, resulting in the child process
exiting.
After executing the exit system call, the OS delivers a SIGCHLD signal to
the process’s parent process to notify it that its child has exited. The child
becomes a zombie process; it moves to the Exited state and can no longer
run on the CPU. The execution state of a zombie process is partially
cleaned up, but the OS still maintains a little information about it,
including about how it terminated.
A parent process reaps its zombie child (cleans up the rest of its state from
the system) by calling the wait system call. If the parent process calls
wait before its child process exits, the parent process blocks until it
receives a SIGCHLD signal from the child. The waitpid system call is a
version of wait that takes a PID argument, allowing a parent to block while
waiting for the termination of a specific child process.
Figure 6 shows the sequence of events that occur when a process exits.
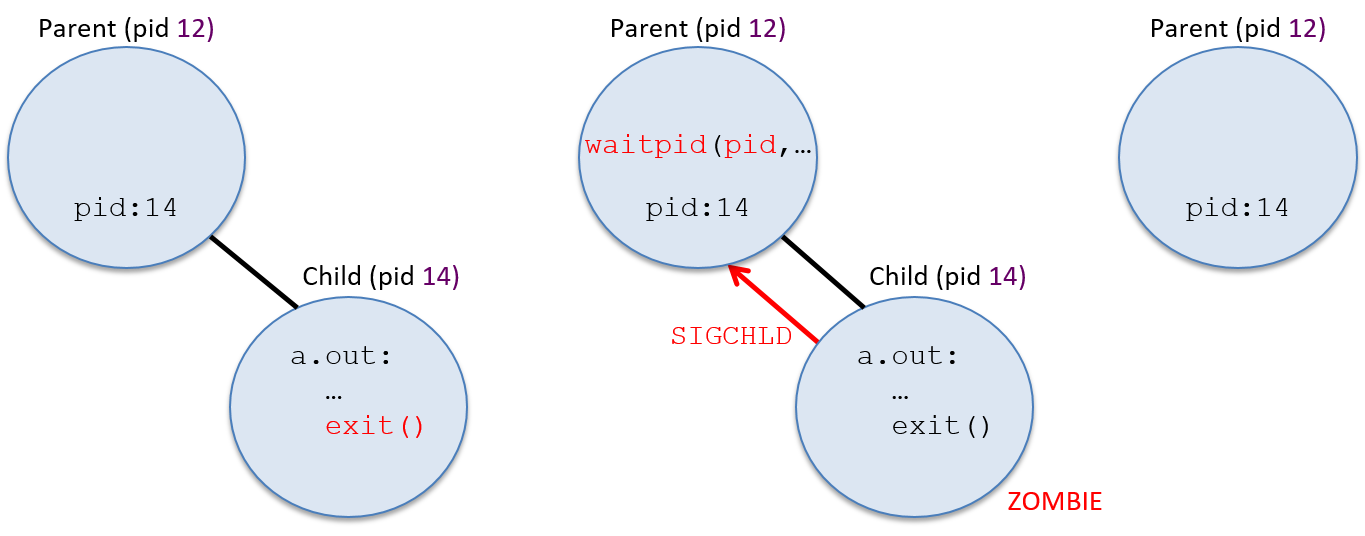
Because the parent and child processes execute concurrently, the parent may call
wait before its child exits, or the child can exit before the parent
calls wait. If the child is still executing when the parent process
calls wait, the parent blocks until the child exits (the parent enters
the Blocked state waiting for the SIGCHLD signal event to happen). The
blocking behavior of the parent can be seen if you run a program
(a.out) in the foreground of a shell — the shell program doesn’t print
out a shell prompt until a.out terminates, indicating that the shell parent
process is blocked on a call to wait, waiting until it receives a SIGCHLD
from its child process running a.out.
A programmer can also design
the parent process code so that it will never block waiting for a child
process to exit. If the parent implements a SIGCHLD signal handler that
contains the call to wait, then the parent only calls wait when there is
an exited child process to reap, and thus it doesn’t block on a wait
call. This behavior can be seen by running a program in the background in
a shell (a.out &). The shell program will continue executing, print out
a prompt, and execute another command as its child runs a.out. Here’s an
example of how you might see the difference between a parent blocking on wait
vs. a nonblocking parent that only calls wait inside a SIGCHLD
signal handler (make sure you execute a program that runs for long enough
to notice the difference):
$ a.out # shell process forks child and calls wait $ a.out & # shell process forks child but does not call wait $ ps # (the shell can run ps and a.out concurrently)
Below is an example code snippet containing fork, exec, exit,
and wait system calls (with error handling removed for readability).
This example is designed to test your understanding of these system
calls and their effects on the execution of the processes.
In this example, the parent process creates a child process and waits
for it to exit. The child then forks another child to run the a.out
program (the first child is the parent of the second child). It then
waits for its child to exit.
pid_t pid1, pid2, ret;
int status;
printf("A\n");
pid1 = fork();
if (pid1 == 0 ) { /* child 1 */
printf("B\n");
pid2 = fork();
if (pid2 == 0 ){ /* child 2 */
printf("C\n");
execvp("a.out", NULL);
} else { /* child 1 (parent of child 2) */
ret = wait(&status);
printf("D\n");
exit(0);
}
} else { /* original parent */
printf("E\n");
ret = wait(&status);
printf("F\n");
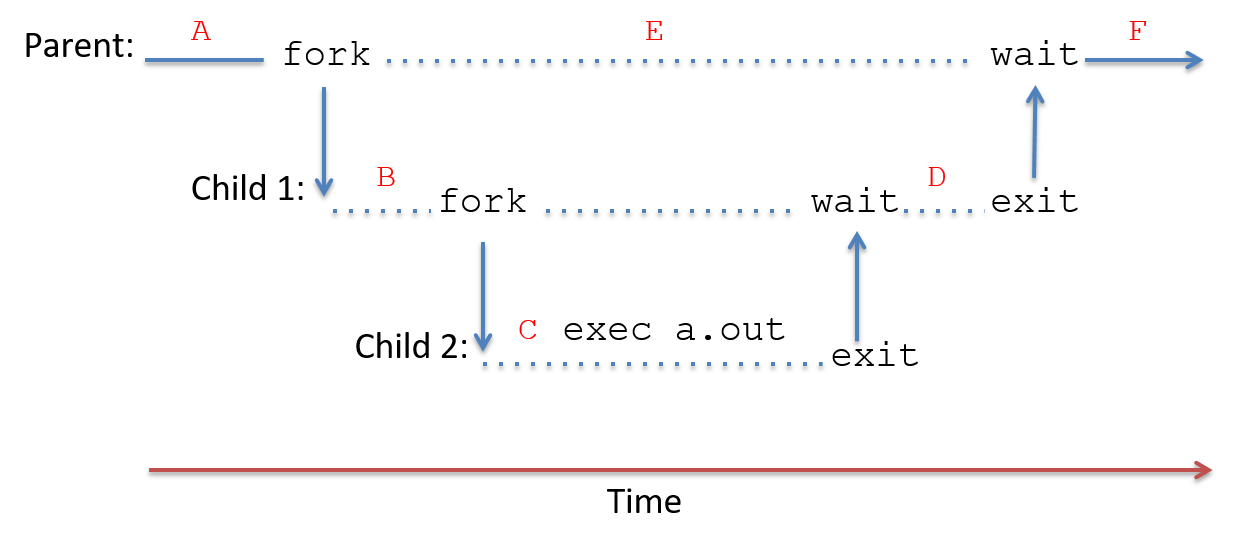
}Figure 7 illustrates the execution time line of process
create/running/blocked/exit events from executing the above example. The
dotted lines represent times when a process’s execution overlaps with its child
or descendants: the processes are concurrent and can be scheduled on the CPU in
any order. Solid lines represent dependencies on the execution of the
processes. For example, Child 1 cannot call exit until it has reaped its exited child
process, Child 2. When a process calls wait, it blocks until its child exits.
When a process calls exit, it never runs again. The program’s output is
annotated along each process’s execution time line at points in its execution
when the corresponding printf statement can occur.
After the calls to fork are made in this program, the parent process and
first child process run concurrently, thus the call to wait in the parent
could be interleaved with any instruction of its child. For example, the
parent process could call wait and block before its child process calls
fork to create its child process. Table 2 lists all
possible outputs from running the example program.
| Option 1 | Option 2 | Option 3 | Option 4 |
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
The program outputs in Table 2 are all possible because the
parent runs concurrently with its descendant processes until it
calls wait. Thus, the parent’s call to printf("E\n")
can be interleaved at any point between the start and the exit of its
descendant processes.